
We evaluate REED-VAE across a variety of image editing scenarios:
Subject-Guided Editing

Text-Guided Editing

Mask-Guided Editing

Multi-Method Editing

While latent diffusion models achieve impressive image editing results, their application to iterative editing of the same image is severely restricted. When trying to apply consecutive edit operations using current models, they accumulate artifacts and noise due to repeated transitions between pixel and latent spaces. Some methods have attempted to address this limitation by performing the entire edit chain within the latent space, sacrificing flexibility by supporting only a limited, predetermined set of diffusion editing operations. We present a re-encode decode (REED) training scheme for variational autoencoders (VAEs), which promotes image quality preservation even after many iterations. Our work enables multi-method iterative image editing: users can perform a variety of iterative edit operations, with each operation building on the output of the previous one using both diffusion based operations and conventional editing techniques. We demonstrate the advantage of REED-VAE across a range of image editing scenarios, including text-based and mask-based editing frameworks. In addition, we show how REED-VAE enhances the overall editability of images, increasing the likelihood of successful and precise edit operations. We hope that this work will serve as a benchmark for the newly introduced task of multi-method image editing.
We evaluate REED-VAE across a variety of image editing scenarios:
Subject-Guided Editing
Text-Guided Editing
Mask-Guided Editing
Multi-Method Editing
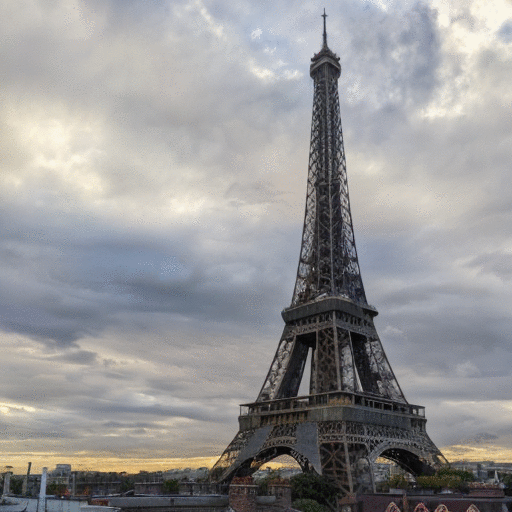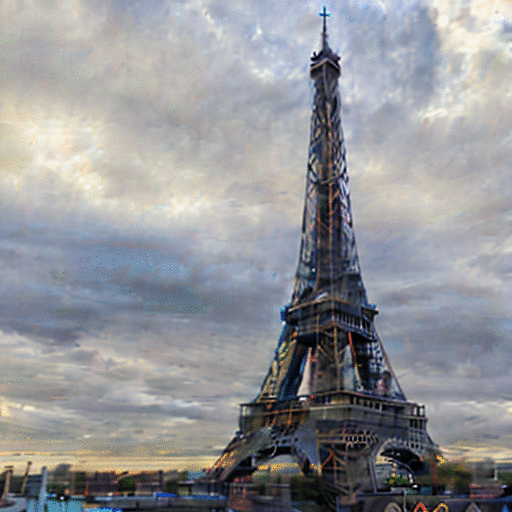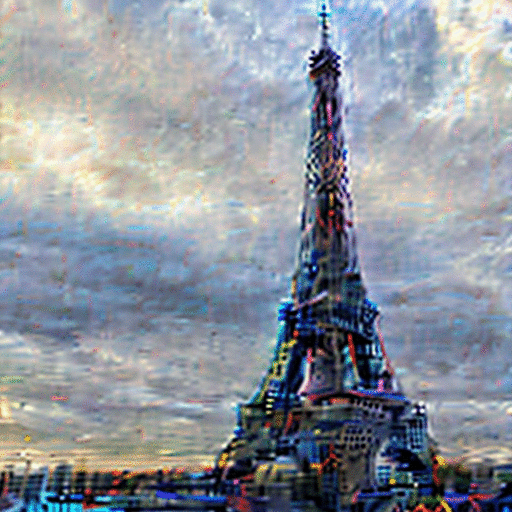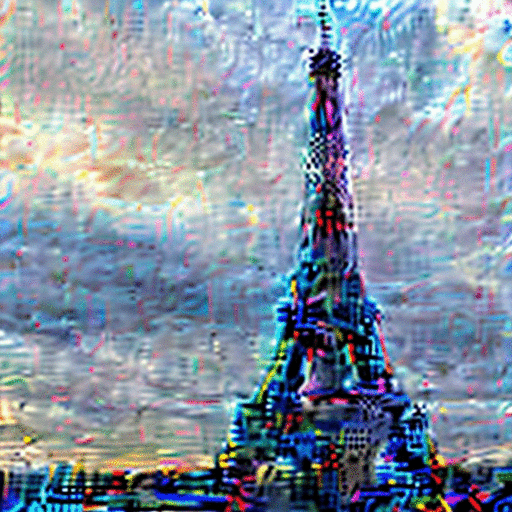
Vanilla-VAE

REED-VAE

Vanilla-VAE

REED-VAE
@misc{almog2025reedvae,
title={REED-VAE: RE-Encode Decode Training for Iterative Image Editing with Diffusion Models},
author={Gal Almog and Ariel Shamir and Ohad Fried},
year={2025},
eprint={2504.18989},
archivePrefix={arXiv},
primaryClass={cs.GR},
url={https://arxiv.org/abs/2504.18989},
}